
El presupuesto de rastreo es un concepto que hay que tener muy presente en páginas web grandes.
Los robots de Google que rastrean todas las webs consumen un presupuesto limitado de URLs de cada web.
Si una web es muy pequeña, probablemente la rastree por completo cada vez que el robot pasa por ella, pero si una web consta de muchas URLs, Google va a tener que limitar su rastreo a aquellas que considere más relevantes.
Si tienes una web pequeña este no es un factor que te deba preocupar, pero en webs medianas y grandes es uno de los factores prioritarios en la planificación SEO.
¿Cómo sabemos si Google está rastreando una URL?
Google nos da esta información desde la SERP. Al lado del título puedes ver un triángulo invertido que te permite ver la versión cacheada de la web. Al hacer click verás un cuadro de texto con la fecha en la que Google rastreó esa URL por última vez.
Haz una búsqueda en Google de site:midominio.com y verás las URLs indexadas de tu web. En este ejemplo vemos dónde se accede a la versión cacheada de una URL desde Google:
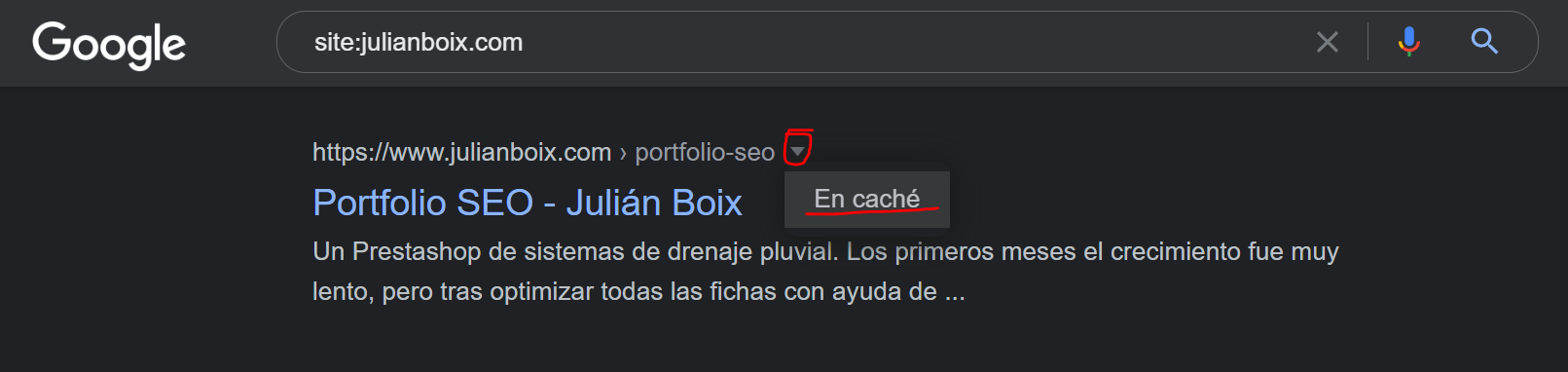
No hay forma de extraer esa información de todas las URLs de la web de forma masiva, pero tampoco es necesario. Lo que sí deberías revisar es la fecha de rastreo de los diferentes verticales de la web: página de inicio, categorías, productos, blog…
Te darás cuenta de cuáles son las páginas más importantes para Google ya que son las que rastrea con más frecuencia. Por lo general los productos se rastrean con menos frecuencia que las categorías, los artículos más antiguos del blog se habrán rastreado por última vez hace mucho tiempo y la página de inicio nos indicará la última vez que Google rastreó la web.
En realidad sí hay una forma de extraer la información de forma masiva: utilizando alguna herramienta de automatización como explico en el artículo.
¿Cómo elige Google las páginas más relevantes?
Lo primero que debes saber es que la página de inicio es la primera en ser rastreada, seguida de las páginas más enlazadas (es el caso de las URLs en el menú y en el footer).
Para que una URL sea relevante para Google tienes que tener en cuenta:
- Enlaces que dirijan a ella: si una página tiene varios enlaces internos hacia ella es más probable que la rastree con frecuencia, ya que los robots siguen los enlaces de la web para descubrir nuevas páginas.
- Nivel de profundidad bajo: cuantos menos clicks tengas que hacer para llegar a una página partiendo de la página de inicio más fácil va a ser para Google llegar hasta ella. Además, se entiende que una página es muy poco relevante si está escondida para el usuario.
- Frecuencia con la que haces cambios en la página: como Google no tiene recursos que derrochar, si pasa varias veces por una página y no detecta cambios con el tiempo va a dejar de rastrearla con frecuencia, ya que entiende que vas a dejar el mismo contenido que él ya tiene en caché.
¿Cómo optimizar el presupuesto de rastreo?
Como he dicho, en webs pequeñas no es necesario optimizar nada, pero en webs medianas y grandes tendrás que revisar qué URLs del total de tu web son prescindibles en cuanto a indexación.
Seguro que no todas las URLs de tu web llegarán a posicionar, tan solo tienes que hacerte la siguiente pregunta: ¿Hay alguna búsqueda que pueda hacer un usuario para la cual le gustaría encontrarse esta página en primera posición de Google? Esa pregunta hace referencia a lo que se conoce como “intención de búsqueda”.
¿Esta página tiene intención de búsqueda? Si la respuesta es que no (o tal vez en un caso muy remoto), es mejor que la desindexes para mejorar el presupuesto de rastreo y potenciar las URLs que sí tienen intención de búsqueda.
Si no hay ninguna ruta concreta que identifique las URLs que quieres desindexar, tendrás que entrar a cada una de ellas y añadir un “no index”
meta name=»robots» content=»noindex, nofollow»
Pero no siempre es necesario hacer la desindexación una por una. Muchas veces vas a encontrar verticales enteros dentro de tu web que no tienen intención de búsqueda, por lo que la optimización consiste en marcar como no indexable la ruta de URL entera.
Para impedir que Google rastree un vertical entero puedes marcarlo como disallow en el archivo robots.txt de tu web. Este es un ejemplo:
User-agent: * Disallow: /blog/En mi artículo sobre optimización de robots.txt hablo más en profundidad sobre cómo utilizar este archivo para controlar este fichero de la mejor forma posible.
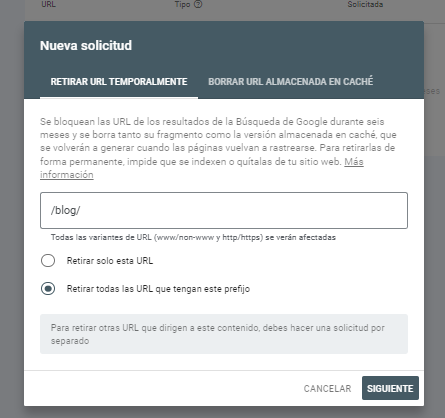
Además de impedir que se rastree, si queremos que Google desindexe el vertical tendremos que utilizar Google Search Console e indicar la ruta que queremos que elimine de su índice:
La mejor forma para encontrar las URLs indexables que deberías eliminiar es utilizando la herramienta Screamingfrog.
Esta herramienta dispone de un gráfico de rastreo que te permitirá descubrir rutas que tal vez ni sabías que existían en la web
Las 4 primeras visualizaciones son muy útiles para explorar la web desde un punto de vista SEO, pero la que he utilizado en este caso es el Diagrama de rastreo forzado.
Este gráfico es ideal para analizar el crawl budget porque nos da justo la información que necesitamos: en color verde verás las rutas indexables y en rojo las no indexables. Conforme van alejándose del centro más nivel de profundidad hay.

Consejos sobre la optimización del presupuesto de rastreo:
- Revisa que las páginas que vayas a desindexar no te traigan tráfico.
- Prioriza la optimización del presupuesto de rastreo si tu web es muy grande, seguramente será un quick win
- Utiliza robots.txt para desindexar directorios enteros.
- No tengas miedo de desindexar páginas siempre que sepas que no tienen intención de búsqueda.
- Las páginas de contenido vacío son las primeras que deberías desindexar, ya que no te aportarán nada positivo.


